














- Semiconductor Technology Now
Topics
Technology
Voice recognition technology hits a snag
As mentioned at the beginning, however, VUIs did not become the mainstream until very recently.
“No significant progress has been made in voice recognition technology in the last decade,” says Prof. Ito, who had done voice recognition research at the Electrotechnical Laboratory (ETL; now National Institute of Advanced Industrial Science and Technology or AIST) and also participated in the development of Julius.
Why is it, then, that VUIs like Siri are coming into the spotlight lately? “It’s not that the voice recognition technology itself has improved,” Prof. Ito explains. “The external factor that computers and network processing have become faster has more to do with it. Siri, for example, processes voice using cloud computing rather than doing it on each individual terminal. The technology to isolate human voice from the ambient noise has also made significant strides which, together with the diffusion of smartphones, helped to boost VUIs.”
In building a language model for Julius, Prof. Ito sampled 200 million words from newspaper and web articles. In contrast, companies like Apple and Google can extract far larger sample data from their countless users to keep refining their acoustic and language models.
As for Siri, some clever tricks to pique the users’ interest are also boosting its popularity. Siri’s character (female in the U.S.) has spawned many fans, who tolerate its occasional oddball answers with good humor. In any case, there is little doubt that only those corporations large enough to handle big data can lead voice recognition research in the foreseeable future. One might say the overwhelming quantity of data translates into better quality of voice recognition. That is why public institutions like universities are increasingly finding it hard to continue with this research theme.
For this reason, Prof. Ito’s lab at Hosei University is shifting the focus of voice recognition research from text input to more affective applications, such as speaker recognition and analysis of singing voice. Specifically, the lab is developing a system that can identify a speaker by recognizing his/her speech characteristics out of multiple speakers in conference, and a system that analyzes singers’ use of normal voice and falsetto and offers singing advice.
Can a computer with emotions be built?
While HMM and n-gram methods are the mainstream of voice recognition today, they have their limitations, too. For one thing, voice recognition based on these two methods is incapable of figuring out the context or the speaker’s emotions.
Take the simple sentence, “I hate you,” for example.
By listening to the tone of voice, we humans can easily figure out if the speaker is serious or just joking. As the display of emotions is fleeting, however, it is difficult to build an affective model even if massive sample data were collected. That is why research in this area has seen little progress so far.
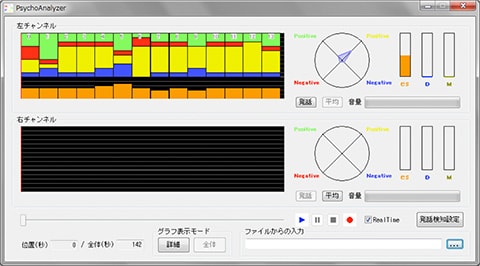
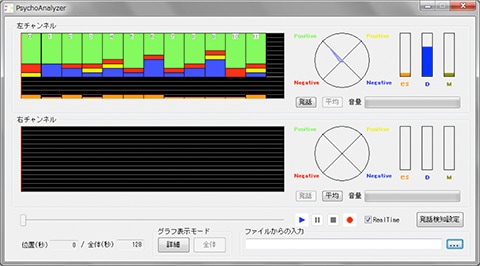
Dr. Shunji Mitsuyoshi, CEO of AGI Inc. and adjunct lecturer at the University of Tokyo Graduate School of Engineering, is taking a unique approach to this problem. He uses the proprietary technology called Sensibility Technology (ST) to analyze the subject’s voice and determine his/her emotions and stress levels.
We control our voice by changing the shape of our vocal tract. However, the vocal folds are not fully under voluntary control, since they are connected to the hypothalamus (i.e., seat of emotions) via the vagus nerve. Manifestations of involuntary control in our voice could reveal the state of our brain, and that became the central idea behind ST.
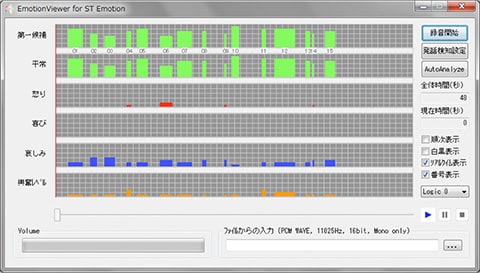
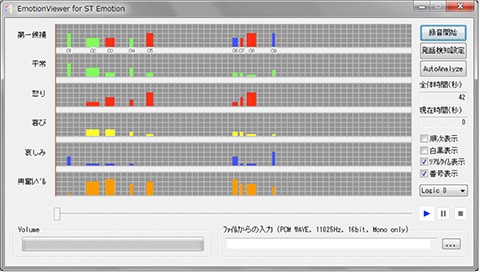
When we are surprised, we gasp. It is accompanied by sudden changes in the depth and rhythm of respiration. By monitoring all those little signs, models corresponding to various emotions can be developed. In a project to develop ST, 2,800 subjects were asked to record voice samples with various emotions, and over 100 volunteers listened to the recordings to figure out the emotions expressed. Based on the data thus obtained, ST was developed as a system for identifying emotions in vocal expressions. The system works regardless of the language involved, be it Japanese, English, or any other. ST can simultaneously detect several emotions including joy, anger, sadness, neutral, humor, and excitement, and the system is used for diagnosing depression and analyzing voice actors’ performances. Because ST’s original approach hardly uses dictionaries for voice recognition or vocal frequency estimates, it became possible to analyze the speaker’s emotions even with a smartphone app using low bit rate services.
 |
 |
 |
 |
Contents
Cross Talk
Visiting Laboratories
Expert Interview
Topics
Report Series

- Motorization, Act II – The Age of Automated Driving

- How Society Will Change in the Digital Age
- Part 1
- What is Digitalization?

- Sports Technology Protecting Athletes and Providing Fairer Refereeing

